
The Bug a Duck Would've Caught
Add one API call between 'agent thinks' and 'agent acts.' A different AI model reviews the plan and says quack — or don't.
Every unreviewed agent action is a coin flip. Ducks don't flip coins.
Your agents are running blind
Same-model self-review is like grading your own exam — same blind spots every time
Manual plan review costs $14,200 per employee per year. Ducks work for free.
Langfuse and LangSmith show you the crash replay. We stop the crash.
GPT reviewing Claude catches structural errors that same-family review misses entirely
Three layers of defense

Cross-Model Verification
GPT reviews Claude. Claude reviews GPT. A second AI family catches blind spots the original model cannot see.

Loop Detection & Circuit Breaker
Detects repeating plan patterns in real-time and recommends circuit-breaker actions before costs spiral.
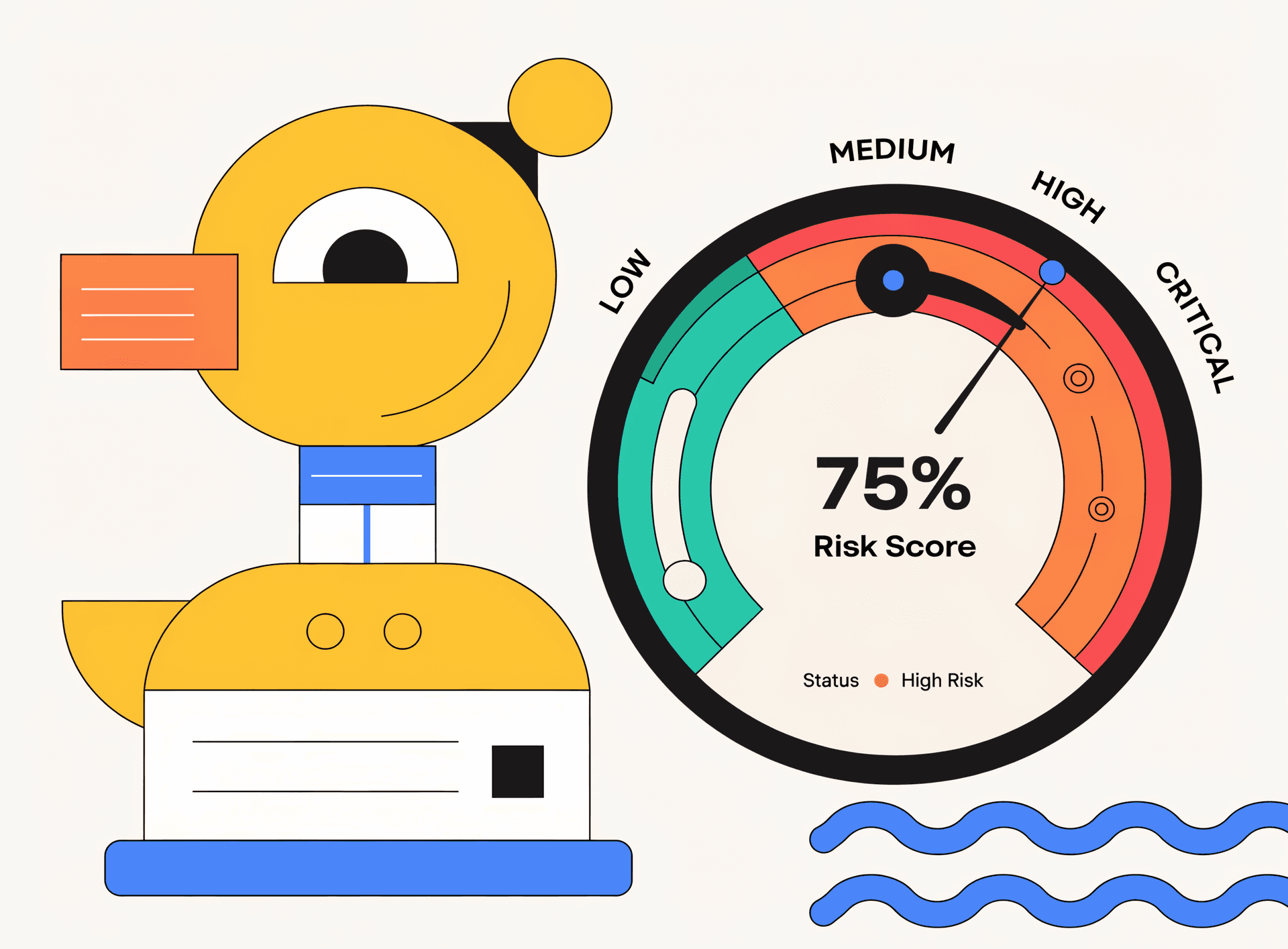
Risk Scores & Verdicts
Every plan gets an approve, flag, or reject verdict with a numeric risk score and actionable suggestions.
Four steps to verified agents
Add the middleware
One import. One line of config. Works with LangChain, CrewAI, and AutoGen.
Agent submits plan
Before any action executes, the plan payload is sent to Rubber Duck for review.
Cross-model verdict
A different model family analyzes the plan and returns approve / flag / reject.
Act with confidence
Your agent proceeds only when the plan is verified. Loops and bad plans never execute.
GPT checks Claude's work. Claude checks GPT's work. Nobody grades their own exam.
“GPT reviewing Claude catches structural errors that same-family review misses entirely”